
So the method to seeking a solution to the 340 should be
As discussed earlier, we must eliminate the material that is junk. The original message looked like this:

Lines 1-3 and 11-13 contain a distinct higher level of randomness than
lines 4-6 and 14-16. This appears to be intentional and indicates
that lines 1-3 and 11-13 contain valid ciphertext whereas
lines 4-6 and 14-16 may be fake.
Additionally, there is The Killer's "ZODAIK" signature at the bottom, which isn't encrypted and hence shouldn't be included in analysis. And there are the two dash marks in the middle, which appear to be guides for writing the text. These items are excluded from the analysis, which leaves the following:

I contend that the only thing that The Killer had time to do between the 408 cipher's decryption and the mailing of the 340 cipher was to create a new, but similar, cipher, and then to make it more difficult to solve by
There was no genius here; just a sort of animal cunning.
Editorial commentary aside, let us proceed.
There appears to be a maximum amount of information zkdecrypto can extract, and the same is true for all other hill-climbing and genetic algorithm methods. If this is the case, it should be possible to determine what that amount of information is. So let's take a look, using a bash script. We'll pipe the results into a text file, use the pseudo-information metric pushed out by zkdecrypto, and graph that.
#!/bin/bash
COUNTER=$((0))
NUM=$((0))
while [ $COUNTER -lt 50 ]; do
NUM=$((40*COUNTER))
echo Iteration: $COUNTER Seconds: $NUM
./zkdecrypto-lite cipher/340.zodiac.nofake3.txt -t $NUM >> zodiac-work-4.txt
COUNTER=$[$COUNTER+1]
done
OK. The graph of runs, with zkdecrypto-lite (the batch version of zkdecrypto) set for 0, 40, 80, and so forth seconds, is presented here
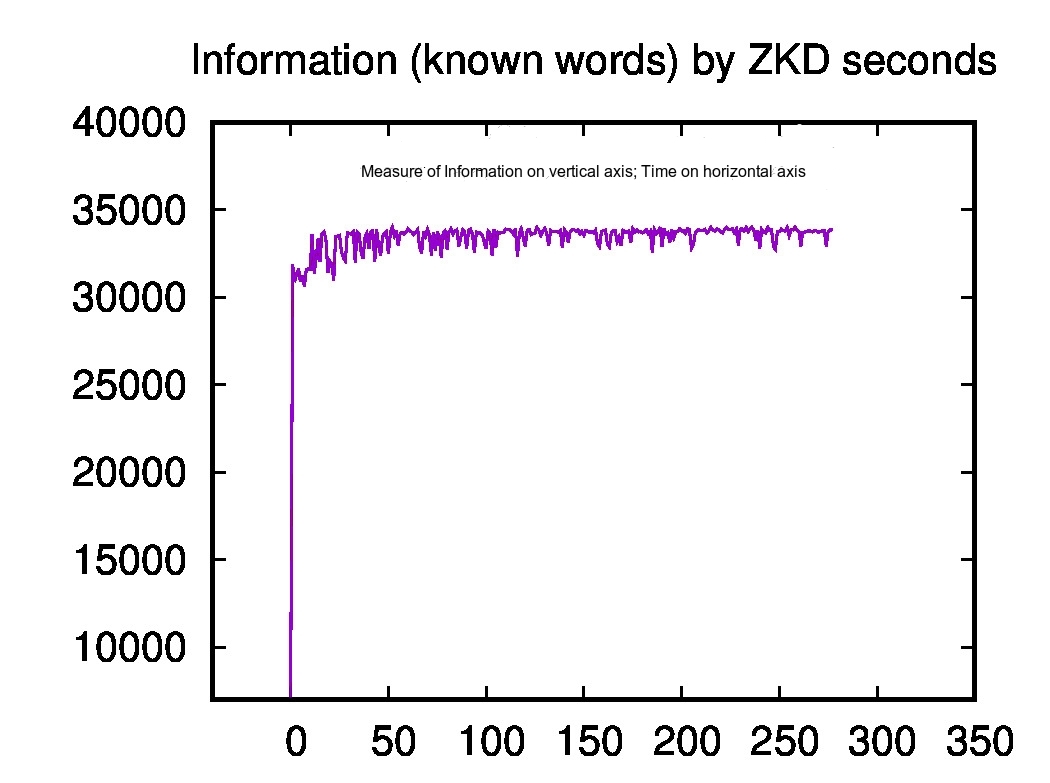
This graph was created in gnuplot, using the commands
set output 'zodiac-work-5c.ps'
set terminal postscript eps size 3.5,2.62 enhanced color \
font 'Helvetica,20' linewidth 2
set yrange [7000:40000]
set xrange [-40:350]
set title "Information (known words) by ZKD seconds"
plot 'zodiac-work-5c.csv' with lines
and then converted to jpg using ImageMagick.
Obviously, there seems to be a limit of about 34000 to the amount of information that zkdecrypto-lite can crank out of the sample; this compared to 44000 for the 408. The limit looks asymptotic; increases in time don't matter. What if I run the software for ten minutes, four hundred times?
There is a surprising consensus between the four hundred models on how much information is to be had, as shown by the summary of the pseudo-information metrics given below by an R analysis.
Information Metrics for 400 ten-minute runs
Min. :32965
1st Qu.:33865
Median :33888
Mean :33896
3rd Qu.:33995
Max. :34000
A graph of the runs shows the same information.

What can we judge from this? zkdecrypto-lite has solved the puzzle; we have what we are going to get. The solution space is resolved as well as it will ever be resolved; we must look at what we have, and make sense of it as best we may.
The solution will involve some letters which are statistically certain (every model agrees on them), some which are probable (most models agree on them), and a few where there is not a consensus. If the model works, almost all of the letters will be statisticallly certain. If it doesn't, then I have wasted my time.
So let's see what we have in the consensus models.
The reasoning behind this solution
Exactly how this solution was derived
The solution itself, with explanatory material
Resources so you can
recreate this solution
improve on this solution
Absolutely the least interesting and important thing here